Thalamus - Our Highly Available Distributed Router for Global Realtime AI Workloads

Wesley Robinson
Techical Member of Staff


Thalamus - Our Highly Available Distributed Router for Global Realtime AI Workloads
Introduction
If you haven’t noticed, GPUs are scarce right now. The global boom in inference has demand growing faster than supply can keep up, and at Cerebrium that means we can't just deploy in one region and let a load balancer sort the rest out. To keep capacity available, our customers' apps end up spilling out across multiple clusters, in multiple data centers, on multiple continents, and across multiple GPU providers. That's a great answer to the capacity crunch, but it creates a unique problem for us. When a request comes in, which of those clusters should serve it?
That decision has a budget of a few milliseconds, and getting it wrong is expensive for us and our customers. Route a real-time text-to-speech request to a cluster on the wrong continent and we’ve blown the latency budget and lost a customer before their model has even started. Route a training job to the cheapest available cluster without checking health and a training run could fail mid-way throwing away many hours of expensive GPU time.
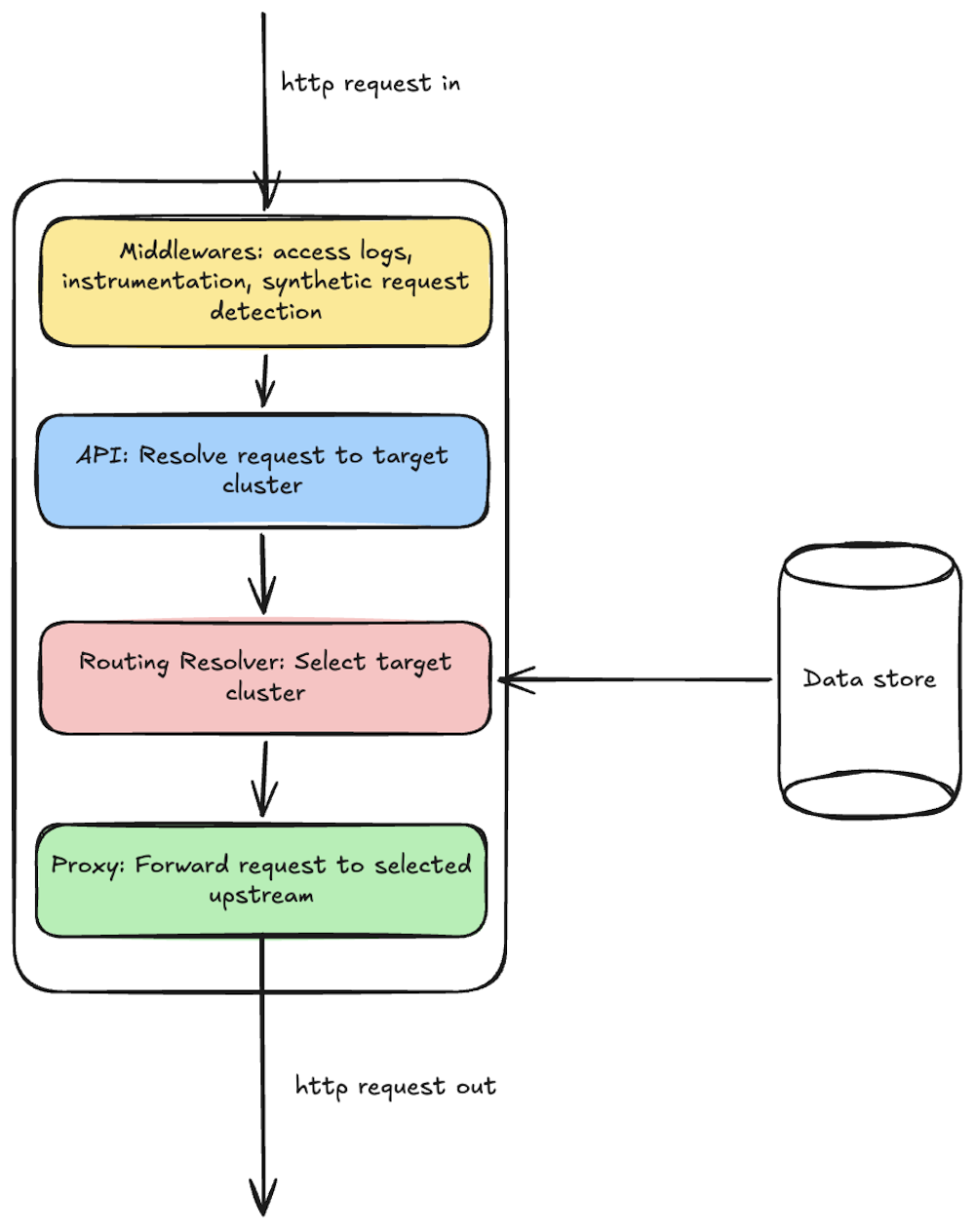
Thalamus is the service that makes that decision. It's the routing brain that ensures requests find their way to healthy, cheaper, lower latency Cerebrium clusters. This post is about how Thalamus allows Cerebrium’s customers to focus more on delivery, and less on careful deployment configurations.
The problem
When you deploy an app on Cerebrium, you get a single URL. You shouldn’t have to care about which cluster runs your code - only that some cluster does, and that it does so quickly and reliably. We have to care about it a great deal, an app is only effective if it is available.
If that URL maps to an app running in a single cluster, the problem is contained. A local load balancer has visibility into its own containers directly, knows their state precisely, and routes accordingly. When that URL resolves to an app running across many data centers, the problems compound: given many geographically separated clusters capable of handling the request, where should it go?
Let's say a customer has deployed a hello-world app that pipes a prompt to an LLM and returns the response. It's available in clusters in us-east, eu-west, and ap-southeast, but explicitly not in our us-west cluster. A user in California sends a request.
The first hop is DNS. Geo-DNS can get us surprisingly far - the nameserver hands back the IP of a nearby Cerebrium ingress - but it can't help with the actual routing decision. DNS doesn't know which clusters this customer's app is deployed to, doesn't know which of those have spare GPU capacity right now, and doesn't know which cluster is healthy. So DNS gets the request close, then hands it off to one of our regional Thalamus instances.

That's where the interesting questions start: how does Thalamus know which clusters can handle this request, and which one should?
Why edge compute and load balancers are not enough
Edge compute solutions are not sufficient for this. AI workloads could be long-lived - a training job or a live stream can hold a single connection open for many minutes, sometimes hours. Most edge-compute platforms cap request duration at well under a minute. So although a routing decision feels like an edge problem, the proxying that follows it is decidedly not.
‘Traditional’ load balancing solutions like round robin or least connections alone are not fit for purpose here. It all boils down to latency. In-cluster load balancers typically balance across nearby, mostly interchangeable workers inside a single cluster or region. New resources becoming available can be broadcasted almost instantly through chatty Raft-esque consensus algorithms that guarantee consistent state when a request comes in for balancing. This kind of protocol only works when updates are fast. Thalamus meanwhile must make a global decision across heterogeneous resources: different clusters, regions and providers that are often oceans apart, so cannot rely on consistent state.
Distributing state - push, don't pull
Thalamus needs two kinds of information to decide where a request goes: static and dynamic.
Static state is the stuff that only changes at predictable events like which clusters an app is allowed to run on, or a region restriction for compliance. It changes on each deploy and config update - infrequently enough that we can pre-compute it.
Dynamic state is everything else. The number of currently running replicas of a user’s application, and how many of those are currently processing requests. What the current GPU spot price is. Whether each cluster is healthy. This stuff changes constantly and unpredictably, and we can't precompute it.
Once Geo-DNS directs the client to a nearby Thalamus instance, Thalamus needs to decide which upstream cluster can actually serve the workload. It may still be in another region or provider, depending on where the app is deployed, what capacity is available, what hardware it requires, and what compliance rules apply. If an application is deployed close to its users, then more often than not Thalmaus will end up routing to a local instance, which is why Geo-DNS is really helpful here.
The naive solution is to have Thalamus query each cluster on the request path: Do you have capacity? Are you healthy? What's your latency right now? Even at one round trip per cluster, with eight candidate clusters spread across continents, we'd blow the latency budget by multiple orders of magnitude before the first decision was made. Thus, state can never be fetched on the hot path.
Instead, inside every cluster we run a small service (internally we call it cluster-aggregator) whose entire job is to watch what's happening locally and push that information to a central data store that Thalamus reads from. It watches scale-up and scale-down events, tracks running and reserved capacity per app and per GPU type, monitors current node costs, and continuously writes those snapshots upward.
A nice consequence is that when a new cluster comes online, it brings its own cluster-aggregator: No central registry needs updating and Thalamus sees a new cluster appear in the data store and starts considering it for routing automatically.
GPU Jungle Where Dreams Are Cached
It is also worthwhile justifying an architectural decision we made: there is one central data store shared by every Thalamus instance and every cluster-aggregator. At first this decision felt like the wrong shape for a low-latency router. Why put a database in the middle of a routing decision that needs to happen in single-digit milliseconds?
The answer is that the database is not in the middle of the request path. It is the middle of the state-propagation path.
Every cluster continuously pushes local snapshots upward: current replicas, reserved capacity, available GPU types, health, node costs, and recent scaling events. That information is then replicated out to every Thalamus instance, where reads happen locally. On the hot path, Thalamus is not asking a remote database or a remote cluster what to do. It is reading from a local copy of the recent past.
That distinction matters because perfectly fresh global state is not achievable within the routing budget. There is always latency between the cluster and its aggregator, the aggregator and the data store, the data store and each Thalamus instance. Light only travels so fast - and by the time a request arrives - the “current” global state is already slightly old.
Thalamus makes decisions from a local, continuously-synced snapshot. That gives us predictable routing latency, keeps the hot path free of remote calls, and gives every Thalamus instance a roughly consistent view of the recent past that we can inspect and replay. This, plus a few tricks, is sufficient to make a routing decision.
To achieve this we use Turso, a distributed SQLite-style database with embedded read-only replicas that sync from the primary. Each Thalamus instance keeps a continuously synced local copy of the control-plane database. Lookups have a p99 of roughly 500 microseconds, which allows us to spend more of that budget making routing decisions.
Turso’s sync feature is so easy to set up and lookups are so fast, the synced db essentially acts as the best kind of cache: one we didn’t have to build.

The decision pipeline
When a request arrives, Thalamus resolves it to a target app, loads the clusters that can currently serve that app from Turso, and starts building a candidate set of clusters. For each candidate it checks (all from in-process state):
What's the candidate’s current hot, warm, and cold capacity for the app?
What's our latest (moving average) measured network latency to that candidate?
What is the cost of the target hardware in that candidate?
Is the candidate passing health checks?
As a short definition of those capacity tiers:
Hot: containers already loaded with this app, ready right now
Warm: running nodes of the appropriate SKU that can scale a new container in seconds
Cold: provider-side headroom we can burst into, but takes longer
We rank candidate clusters by the best tier they can satisfy. So, if a cluster has any hot capacity, it is instantly preferable over a cluster that only has warm or cold capacity. There's almost no scenario where it's better to cold-start somewhere than to serve from a container that's already running.
Now, with a set of ranked candidate clusters, we need to pick the most suitable one. This is where we must work around the stale data problem. The question we’re trying to answer really becomes which cluster is the most likely to serve this request in the shortest amount of time? Because we cannot know what the exact current capacity spread is, we never pick "the best," we pick probabilistically, weighted by available capacity and then nudged by a pipeline of modifiers. A cluster with more hot capacity, lower latency, and better cache locality is far more likely to be capable of processing any given request right now, but it should not receive every request.
We can also add extra conditions here as needed. One extremely important piece of data to consider is whether or not the apps in that cluster are healthy. Or if the cluster, or even the data center itself is healthy. If not, we disqualify the cluster from the list of candidates. This is done dynamically via a constant stream of health checks, and now we have automatic failover.
This gives us a smoother routing system. We can prefer nearby clusters without letting one region monopolise traffic. We can prefer cheaper capacity when there is plenty of it, but stop caring about cost when capacity gets tight. We can bias workloads toward clusters where they have recently run, improving cache hits and reducing startup time. And we can still enforce hard user or business constraints, like “this app must only run in Europe” for data sovereignty.
Validating the algorithm
A routing system is only tunable if we can explain what it did afterward. Every decision Thalamus makes is logged with the full input context behind it: the target app, candidate clusters, capacity tier, health state, latency estimate, cost inputs, applied modifiers, final choice, and routing reason. Those reasons show up everywhere - metrics, logs, traces, and dashboards - so when a request goes somewhere unexpected, we can always answer why.
This has been especially useful because routing is not a static problem. The “right” decision tree changes as our fleet changes, customer workloads change, GPU pricing changes, and new regions come online.
Since all this data is captured, we can take real production routing events and simulate them against an altered version of the algorithm. That lets us ask questions like:
Would it have reduced median or tail latency?
Would it have shifted too much traffic into one provider or region?
Would it have behaved better during last Tuesday’s incident?
Would this have respected the same customer constraints?
Would this change have improved gross margin?

We also built a synthetic request handler into Thalamus. A synthetic request is one that runs through the real Thalamus routing path against live state, emits the same metrics and logs, but Thalamus never proxies the request to a real upstream cluster. This gives us a safe way to test routing behavior in production for any given customer without actually subjecting their traffic to potentially broken routing rules.
All this means changes to Thalamus routing rules are never guesswork. The goal is not just to know where a request went, it is also to know why it went there, whether it should have, and what would have happened if we had made a different choice.
Results
To validate that the routing layer was not adding meaningful overhead, we compared requests sent directly to customer cluster URLs against requests sent through api.cerebrium.ai, where Thalamus performs the routing decision.
With DNS, TLS, and the connection kept warm, routed requests were within milliseconds of direct cluster calls across the customer’s core endpoints. In some cases they were even marginally faster, which is likely just normal network variance.
That is the bar we wanted Thalamus to clear: global routing, capacity awareness, health checks, and failover without adding noticeable latency to the request path.

Closing thoughts
Thalamus started as a routing problem, given a request and many clusters that could serve it, how can we pick one quickly and correctly? Routing real-time AI workloads is messy business. It requires balancing latency, capacity, health, cost, cache locality, and customer constraints.
So Thalamus is built around that reality: push state frequently, read locally, make probabilistic decisions, and log every decision so we can replay it later.
That last part matters. Routing should not be tuned with vibes. Every change trades off margin, latency, reliability, and placement constraints. By backtesting real production traffic, we can see what would have happened before we change what will happen.
As AI workloads become more real-time, global, and constrained by GPU availability, routing can be the difference that makes your app feel natural and responsive, while also being resilient.
Sign up to Cerebrium if you are looking to build global, low-latency AI applications





