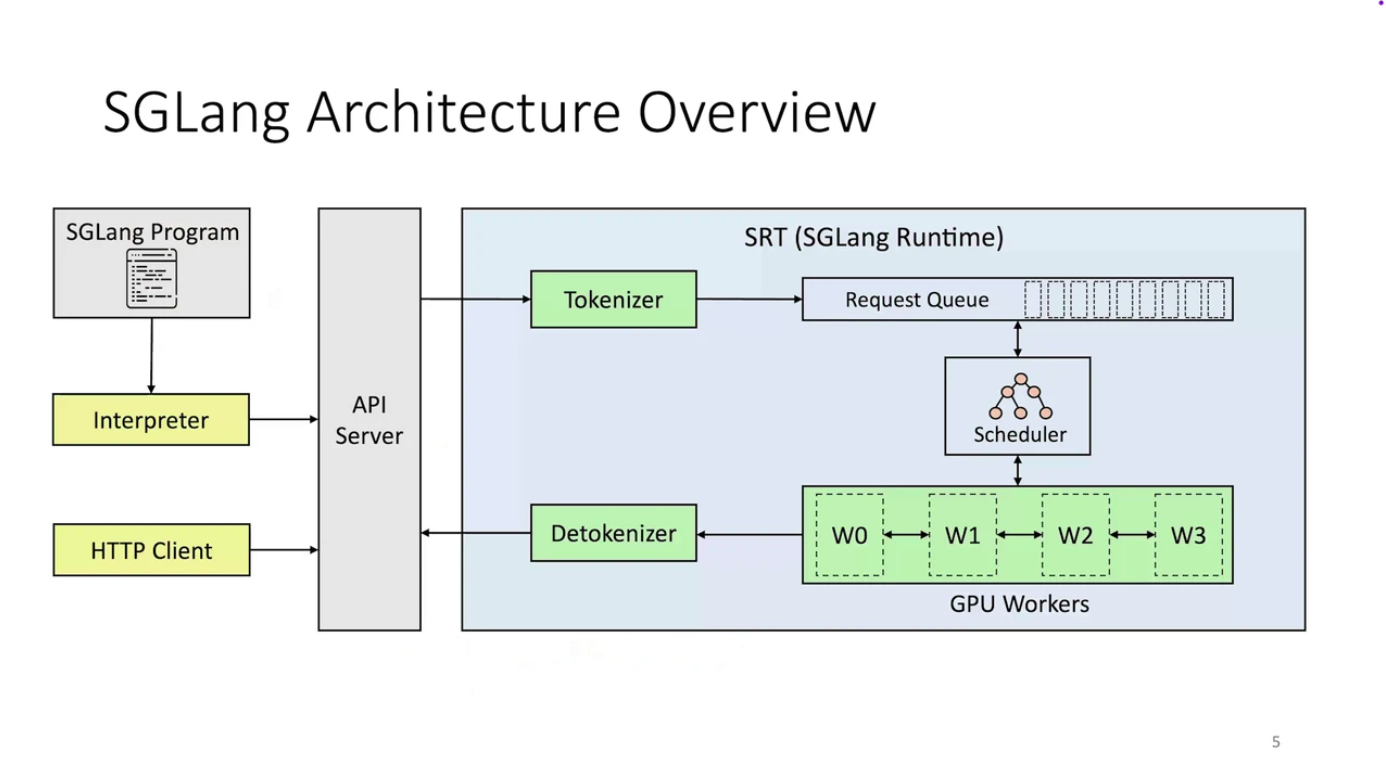
SGLang Architecture
SGLang isn’t just a domain-specific language (DSL). It’s a complete, integrated execution system with a clear separation of functionality:
Here are some frontend primitives for creating multi-step workflows:
For more details, see this article.
You can see the final code sample here
Tutorial
Step 1: Project Setup
Create the project structure:Step 2: Configure Dependencies
The VLM is Qwen3-VL-30B-A3B-Instruct-FP8, which requires significant GPU memory. Thecerebrium.toml defines the environment, hardware, and scaling settings. This configuration uses an ADA_L40 GPU and includes:
- Hardware settings for GPU, CPU, and memory allocation
- Scaling parameters to control instance counts
- Required pip packages: SGLang, flashinfer (the chosen backend), and PyTorch
- APT system dependencies
- FastAPI server configuration for hosting the API
cerebrium.toml with:
Step 3: Implement the Ad Analysis Logic
Cerebrium does not enforce any special class design or application architecture — write Python code as if running locally. The code below sets up the SGLang Runtime Engine (Backend) with FastAPI and loads the model on container startup. The first request incurs a model load, but subsequent requests execute instantaneously. In yourmain.py file:
fork, which runs many prompts in parallel and brings the results together. This enables many simultaneous evaluations with no increase in total latency. The results are then structured in a specific format for the response.
Step 4: Deploy Your Application
Run:
Example Response
fork() for parallel processing and SGLang’s built-in output control.
You can find the complete code for this tutorial in our examples repository.