This example is only compatible with CLI v1.20 and later. Should you be making
use of an older version of the CLI, please run
pip install --upgrade cerebrium to upgrade it to the latest version.Basic Setup
Developing on Cerebrium is similar to a virtual machine or Google Colab. Install the Cerebrium package and log in before proceeding. See the installation docs for details. First, create your project:[cerebrium.dependencies.pip] section of your cerebrium.toml file:
main.py file. This implementation fits in a single file. Start by defining the request object:
prompt parameter is required; others are optional with default values. A missing prompt triggers an automatic error message.
Falcon Implementation
Model Setup
predict function, ensuring model weights load only once at startup.
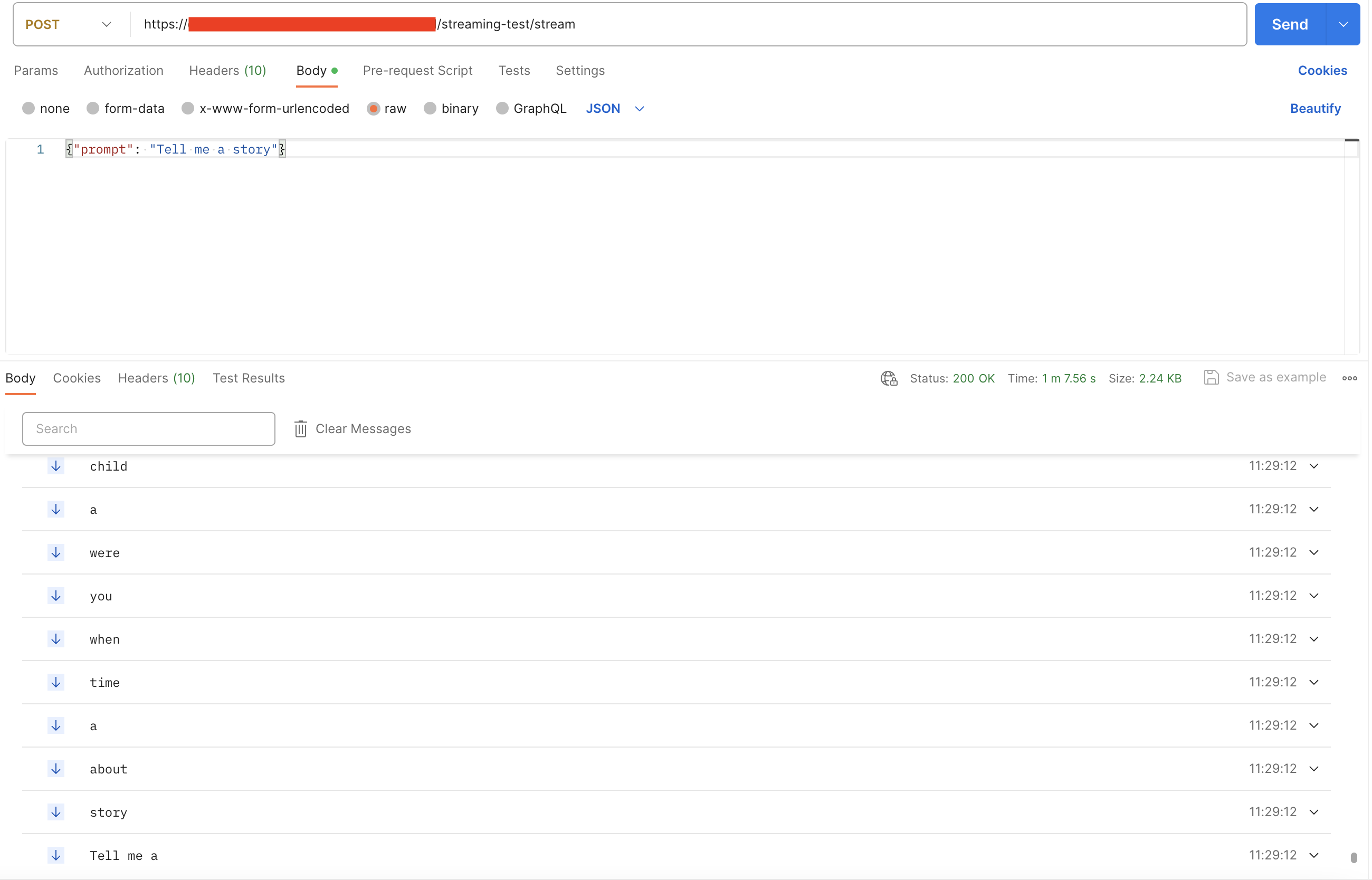
Streaming Implementation
Thestream function handles streaming results from the endpoint:
TextIteratorStreamer to stream model output. The yield keyword returns output as it generates.
Deploy
Configure your compute and environment settings incerebrium.toml:
The endpoint path should include
stream since that is the function name.