


Benchmarking vLLM, SGLang and TensorRT for Llama 3.1 API
At Cerebrium, we have many customers that come to us looking for the most efficient and/or performant way to deploy machine learning models. However, efficient/performant both have different expectations based on user constraints. Some users view the lowest TTFT as the most important metric, whereas others view throughput as the most important. Additionally, various frameworks implement different techniques to optimize for each of these - trading latency for throughput or vice versa.
In this tutorial we will benchmark llama 3.1 70b FP8 across the 3 most popular frameworks comparing TTFT and throughput across various batch sizes running on 1xH100. Below we introduce the uniqueness about each framework and speak about the results. We will not deep dive into the code however you can find the final implementation here
Benchmark Conditions:
The test from my laptop in US-east-1 and the models were deployed to servers located in US-east-1
Average input tokens: 256, average output tokens: 512
We ran a llama 3.1 70B FP8 model on a single H100
Frameworks
Vllm
The vLLM framework is one of the most popular frameworks and is optimized for efficient large language model (LLM) serving, particularly with models like LLaMA 70B. It utilizes a unique “token stream” approach, which allows for overlapping computation and communication, significantly reducing latency. This design is particularly advantageous for batch processing and prompt streaming, enhancing throughput without sacrificing responsiveness. Additionally, vLLM supports various GPU configurations, making it highly adaptable for large-scale deployment scenarios. Its efficiency and flexibility make it an excellent choice for low-latency, high-throughput LLM applications.
You can read more from their initial paper the vLLM paper
TensorRT
NVIDIA TensorRT is a high-performance deep learning inference library focused on optimizing and deploying AI models on NVIDIA GPUs. It provides efficient inference for LLaMA 70B by utilizing mixed-precision and quantization techniques, enhancing both speed and memory efficiency. TensorRT supports diverse optimization strategies, including layer fusion and kernel auto-tuning, making it suitable for low-latency, high-throughput applications. With these capabilities, TensorRT is a preferred choice for deploying large-scale LLMs in production environments.
For further information, visit TensorRT.
SGLang
SGLang is designed for efficient deployment of large models, like LLaMA 3, with a focus on low-latency inference. It introduces optimizations for GPU utilization and dynamic workload distribution, making it ideal for real-time applications. SGLang supports multi-modal interactions and incorporates advancements in prompt processing and token management, enhancing both performance and scalability. This framework is well-suited for production environments where quick response times are critical.
For more information, visit SGLang
TTFT (Time To First Token):
The following benchmark was done with 256 input tokens on 1xH100 of batch size 1. This was the total roundtrip time of a request made to the Cerebrium platform.
vLLM SGLang TensorRT
123ms 340ms 194ms
As you can see, vLLM is the winner of this category offering the lowest TTFT.
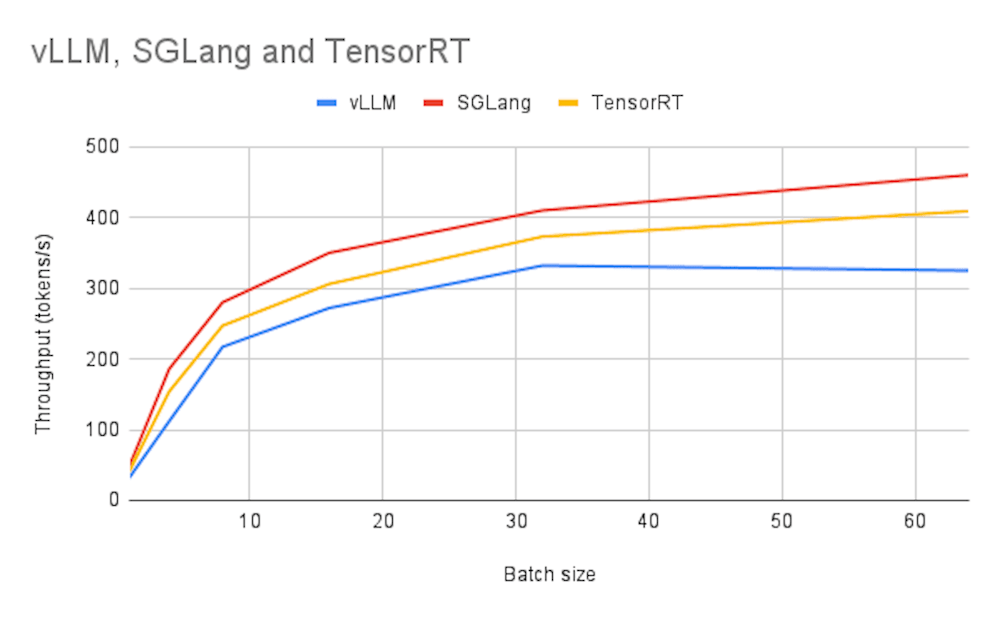
Throughput:
Below we ran a series of benchmarks with 256 input tokens and 512 output tokens across a variety of batch sizes.
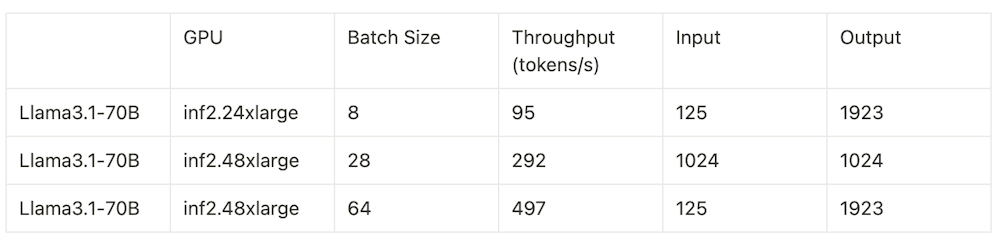
Bonus: Inferentia
If you are looking for a cheaper and more scalable solution (because there isn’t a capacity shortage) you could look into AWS Inferentia Nodes. Below were the results we achieve on a variety of batch sizes.
Conclusion
From our tests, it seems that vLLM is the best framework for use cases looking for the lowest TTFT of 123ms which is extremely quick if you take into consideration network latency. As for throughput use cases, it seems SGLang was a clear winner achieving a throughput of 460 tokens per second on a batch size of 64. Based on your workload, there are many configurations you can try such as using multi-GPU instances and playing with the TP setting which should allow for more performant memory use leading to higher throughput values and lower TTFT.





