Achieving 83% Speed Improvements in Custom Container Images

Yaseen Hamdulay
Member of Technical Staff

Achieving 83% Speed Improvements in Custom Container Images
At Cerebrium, we spend a lot of time reducing the gap between an incoming request and the moment it reaches a running application container: the cold start. For bursty AI workloads, cold starts are sometimes unavoidable. When traffic exceeds the capacity of already-running containers, new containers need to be created. If there are no available host machines for those containers, new nodes need to be started. And if an entire provider or region is out of capacity, traffic may need to spill to another provider or geography, adding even more delay.
We work on reducing each step in that chain. In a previous engineering post, we explained how we sped up container image loading by rethinking image distribution. Once that improved, the next major bottleneck became node boot time.
Node boot time matters because it directly affects how quickly new capacity can come online during demand spikes. The slower a node takes to become ready for scheduling, the longer requests are queued, the worse tail latency becomes, and the more infrastructure we have to keep warm just to avoid multi-minute cold starts. Since Cerebrium runs across multiple providers, we also needed an approach that was transferable across clouds rather than relying on a provider-specific optimization.
In this post, we show how we reworked node startup and initialization on AWS to reduce machine boot time by 83%, cut the long tail of cold starts, and lower the amount of excess capacity we needed to keep running, improving overall utilization. While we focus on AWS here, many of the lessons and optimizations transfer well to other cloud providers.
The problem: machine boot was taking minutes
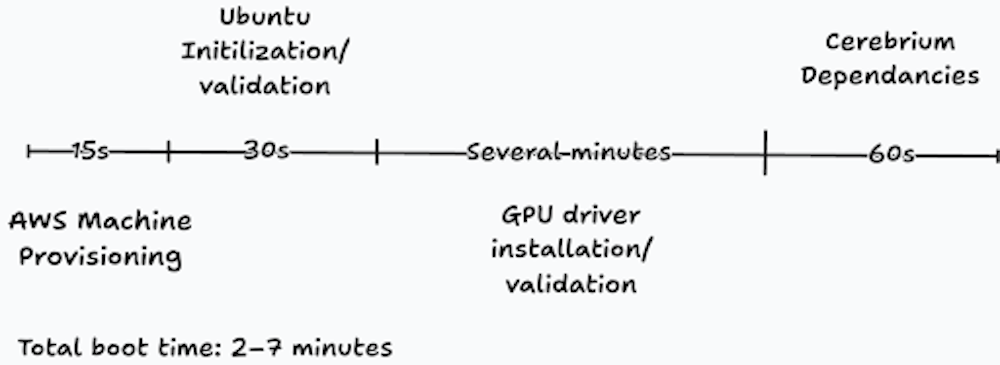
Our original ec2 boot and start process was naive. From the moment we requested a machine to the moment it was ready to run user containers, the process could take anywhere from 2 to 7 minutes.
Breaking it down:
AWS could usually provision a new machine quickly, roughly 15 seconds.
Ubuntu initialization took another 10 to 30 seconds.
GPU driver installation and validation took several minutes.
Attaching and preparing our shared storage layer added roughly 30 seconds.
Platform services needed by customer workloads also had to be prepared before the node could accept work.
Because booting a machine was so slow, we were forced to keep more machines warm than we actually wanted, just to stop tail cold starts from becoming multi-minute events. That increased cost materially and undermined part of the value of a serverless platform.
Our approach: measure first, then remove work
Our approach to improving machine star time was very simple. First, measure every step between instance launch and node readiness. Then, for each step, ask four questions:
Can this be moved to image build time?
Can it be made faster?
Can it run in parallel with other work?
Does it need to happen at all?
Measuring how long each part of the boot process is very easy. Systemd has builtin tools to do this. If you run `systemd-analyze critical-chain snap.kubelet-eks.daemon.service` gives us a detailed view of which services were blocking kubelet from starting and what the dependency chain looked like. A single measurement is not enough.
One important lesson was that single measurements were misleading. Several parts of the boot process had high variance, so we needed repeated measurements to understand both median and tail behavior.
Our machine images are built with HashiCorp Packer. That gave us a useful rule of thumb: if something is not unique to a specific machine at runtime, it should probably happen at image build time instead of on every boot.
Doing Less
The fastest work is the work you do not do.
Pre-baking GPU drivers
The first obvious win was Nvidia driver installation. We were installing drivers at boot, even though there was nothing machine-specific about that step. Moving driver installation into the machine image build process immediately removed at least a minute from startup.
Removing redundant GPU validation
The Nvidia container toolkit also performed GPU validation before containers could run. That added roughly 30 seconds.
In our case, this validation was redundant. Our infrastructure providers already validate GPUs before they hand them to us, and we have other checks in place to detect unhealthy hardware. So we removed this step entirely.
Trimming platform startup overhead
Cerebrium runs a set of platform services alongside customer workloads. These handle things like secret management, shared storage mounted at /persistent-storage, lazy image loading, logging, monitoring, and other foundational capabilities.
The issue was that booting a machine required loading more than 17 GB of platform container images. Even with lazy loading, that was still a substantial amount of work.
So we applied the same methodology: could we move this to build time, reduce it, or avoid it?
Pre-baking images was not enough
Our naive attempt at downloading the platform container images at machine build time and pre-baking them resulted in a substantial increase to our machine boot time. At boot time we copy all container images from the boot image to faster NVMe storage. Our containerd root is set to be on the NVMe drive and images could not be loaded from the boot drive. Copying from the boot image drive to NVMe took several minutes even though it was copying to very fast NVMe storage as the source boot image is very slow to read from only achieving around 10 MB/s.
Instead of copying we tried to bind mount the containers from the boot drive to the NVMe drive. This didn’t work as containerd uses the linux kernels overlayfs to mount a writeable layer on top of the container images. Overlayfs does not support the underlying read only image being a squashfs filesystem or bind mounds.
What did end up working was symlinking the images from one drive to another. This way we could avoid the slow copying step.
Measuring once more we found that this was still slower than the previous approach of downloading the images from the internet onto the NVMe drive directly. The network is really fast but surely it should be faster than reading from our local image?
The hidden bottleneck: lazy-loaded AMI blocks
It turned out that on AWS when creating a new machine from an Amazon Machine Image the new boot drive created from the image lazily pulls blocks of the AMI into the drive from S3. This explains the very slow copy times earlier.
Amazon is aware of this problem and provides a feature called Fast Snapshot Restore that removes this problem entirely for a hefty fee. When this feature is enabled you can read from the boot drive at the full throughput allocated to the drive from instance start for the surprisingly substantial cost of $540 per availability zone per image. But this saves us almost a minute of boot time and is worth the cost!
Reducing Ubuntu initialization variance and Variability
One of the more frustrating issues was not just Ubuntu initialization time, but how inconsistent it was. Some boots were completed quickly. Others took much longer for reasons that felt almost random.
A major contributor was snap.
Some of our services depended on snap packages, and on first boot snap would “seed” those packages, which could take up to 10 seconds. Even after that, snap introduced enough runtime overhead and variability that it was hard to justify for a system that needs to become ready as quickly and predictably as possible.
We removed snap from our machine images entirely and replaced those dependencies with apt packages or directly managed binaries.
We also found several services that genuinely needed to run, but did not need to block node readiness. Those were restructured so they could initialize later or in parallel rather than sitting on the critical path.
That included work such as:
parts of Nvidia initialization,
waiting for network readiness earlier than necessary,
and other services that kubelet did not actually need before the node could begin progressing toward readiness.
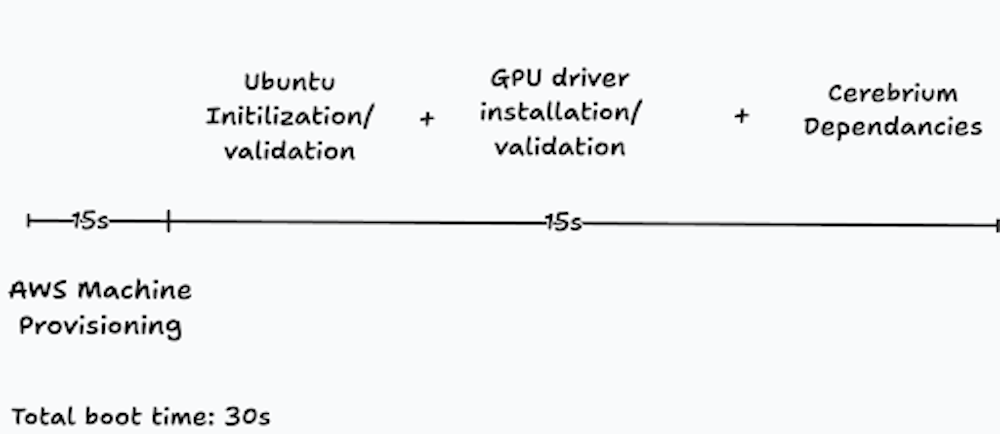
Reducing node boot time came down to systematically removing work from the critical path. We measured each stage of the boot process, moved anything non-machine-specific to image build time, removed steps that were redundant, and delayed or parallelized work that did not need to block a node from becoming ready. In practice, that meant pre-baking Nvidia drivers into the machine image, removing unnecessary GPU validation, cutting snap-related initialization overhead, reducing the amount of platform setup performed at boot, and addressing storage bottlenecks caused by how machine images are loaded on AWS.
The result was a dramatic improvement: we reduced machine boot time from 2–7 minutes to under 30 seconds. That significantly cut the long tail of our cold starts and allowed us to bring new capacity online fast enough for bursty, latency-sensitive AI workloads.
Reducing machine boot time improves both sides of the equation. Users get faster responses during traffic spikes, and we can run the platform more efficiently by bringing capacity online as needed instead of permanently overprovisioning machines just to mask slow startup times. For a serverless AI platform, that means better user experience, higher utilization, and better infrastructure economics.





